
A humble beginning
Online communication is what drives the modern world. Little packages of information floating from sources like your “Add to cart” button to Amazon’s servers; which respond nearly instantaneously in kind. However; online communication isn’t easy. My first experience with a WebSocket interaction was fairly early in my decision to take learning programming seriously. After learning about Socket.IO one afternoon while looking for learner projects I found myself way in over my head as I tried to piece together Stack Overflow code with my own creation of a ‘Rock-Paper-Scissors’ game so that two users could play together from different web browsers. Many hours later I had my first WebSocket pushing a message and a real console.log() coming through on the other end. By no means was the code “clean code” but the message got through. Transition to building API’s and WebSockets in a beautiful orchestration of data being tossed around in a live service application. I felt as though I understood the system and how it communicated with clients.
Then came the term “Pub/Sub”.

An honest truth
For a long time Pub/Sub lived in my head as one of those phrases you nod along to in architecture discussions. You know the move. Someone draws boxes, arrows multiply like rabbits, and everyone agrees this is “the scalable solution.” Meanwhile internally your brain is whispering -- Yes, but… who’s actually talking to whom? And how does the message know where to go?
Over the last couple of months the systems I’ve been working on have been evolving in a very specific way. From a single application into a set of independently running services deployed across Kubernetes pods. Something that I myself knew very little about as the transition occurred. Until it had a direct effect on me.
This article assumes only a light familiarity with distributed systems. If some names are new, these references help anchor the ideas:
Amazon SNS (Simple Notification Service) – managed publish/subscribe messaging
Amazon SQS (Simple Queue Service) – durable message queues
Amazon EKS (Elastic Kubernetes Service) – running many copies of your app
LocalStack – running AWS services locally
The Problem: When “Just Send the Message” Stops Working
In a live service application that communicates with clients over WebSockets everything feels simple… until it isn’t.
Imagine a user takes an action. Maybe they click a button, submit a form, or trigger some state change. That action needs to do at least two things.
- Return an immediate response so the UI feels quick and speedy.
- Notify one or more connected clients (possibly other users) that something has changed.
When everything runs in a single-process you can keep it simple. You keep some in-memory state. You loop over active WebSocket connections. You send messages directly. It feels cozy. I felt cozy.
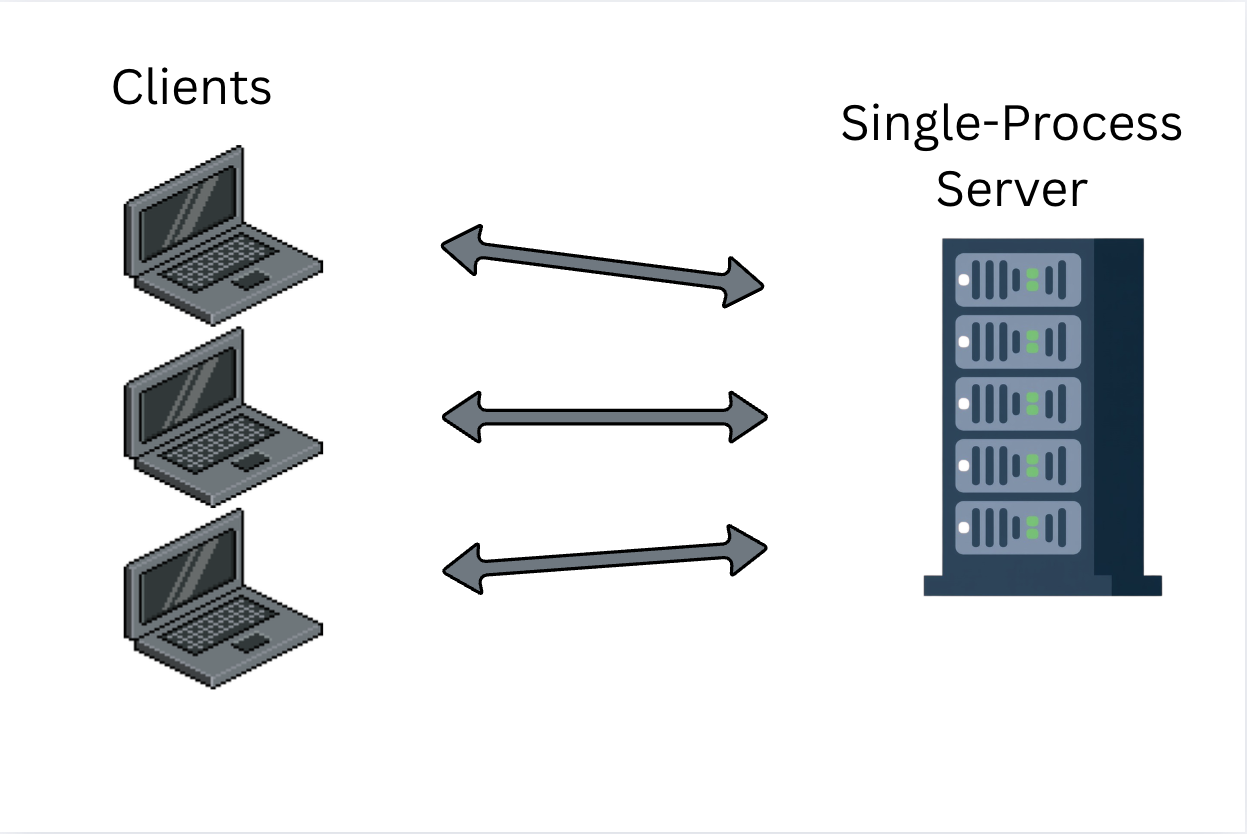
Now we introduce the idea of a distrubuted system.
Distribution Makes Pub/Sub Mandatory
While there are other options when choosing how you will make your single-process application a distributed one, our team chose to utilize the Amazon provided Kubernetes service.
A breif look into the stars
At a high level Kubernetes is a container orchestration platform. It runs your application inside containers. It then groups those containers into pods and takes responsibility for starting them, stopping them, independently restarting them, and scaling them as needed. It’s designed to run the same way whether you’re on a laptop, a data center, or a cloud provider and it’s very good at that job. This is really quite amazing but can introduce some real challenges when developing a live service application.
Kubernetes pods are ephemeral. They can be restarted at any time and duplicate horizontally. They do not share memory with one another. From Kubernetes’ perspective your application is not a process but rather a fleet of processes.
This means you lose a few comforting assumptions all at once. You can no longer assume that the process handling an API request is the same process holding a client’s WebSocket connection.
Your app in space!
Regardless of the service that you choose, suddenly your application isn’t one thing. It’s a small constellation of pods (indivdually deployed containers running your code), any of which might receive the request and none of which know who else is currently connected. One pod receives the API call. Another pod owns the WebSocket connection of the caller. A third is busy doing background work and humming quietly to itself.
At this point shouting across the room no longer works.
Imagine a neighborhood of identical houses. They were all built from the same blueprint so they look identical from the outside. But the people inside, the conversations happening, and everything they know can be completely different from house to house. Kubernetes gives you more houses whenever traffic increases and is able to tear some down when they’re no longer needed.
Enter Pub/Sub (Cue Confusion)
So the journey of ensuring prolonged communication began. Diving into Pub/Sub head on!
Pub/Sub (Publish/subscribe) systems solve a very specific problem by decoupling senders from receivers. The publisher doesn’t care who receives the message. The subscribers don’t care who sent it. Everyone agrees on the shape of the message and the topic it belongs to. This gives you a way to say, “This happened,” without caring who is awake or currently home to hear it. That decoupling is the only way the system can remain coherent as it scales and reshapes itself underneath you.
That’s the theory. The practice… well that’s where my brain locked up for a while.
Using Amazon Web Services Pub/Sub tooling, specifically AWS SNS. Means thinking in terms of topics, subscriptions, delivery policy, dead-letter queues, and permissions. None of these concepts are individually hard. Collectively they form a mental maze.
I spent a lot of time staring at the AWS Console thinking, Why is this so complicated?
The answer as it turns out is that once your app becomes distributed communication stops being a convenience and becomes a system you have to design. It’s no longer “just send the message” anymore. It’s infrastructure.
The Day It Finally Clicked
Eventually I had it. The eureka moment!
Here’s the metaphor that saved me.
A topic is a train station.
A subscription is a train.
A message is cargo.
When a message is published (sent into a topic) it arrives at the station. Every train currently scheduled to leave that station (subscription listening to a topic) picks up a copy of the cargo and attempts to deliver it to its destination (a subscriptions endpoint).
Some trains go to HTTP endpoints.
Some go to queues.
Some derail and dump their cargo into a dead-letter yard where someone can inspect what went wrong.
Unlike a train delivering cargo – Pub/Sub does give you the opportunity to retry a failed delivery. This is typically handled by rules that are defined in a deliver policy on the subscription. Allowing for a slow-drip of retries before finally backing off; either by forgetting the message ever existed or moving that message into a defined redrive policy. A redrive policy determines where messages go after retries are exhausted, usually an SQS queue used as a dead-letter-queue.
The publisher doesn’t track trains. The publisher doesn’t know destinations. They just drop cargo at the station and walk away.
Take a user invitation flow for example. When someone invites a teammate via an API the publisher pod drops a 'user_invited' message onto a 'invitations' topic. One subscription train delivers it to an SQS queue for an email service to pick up and send. Another goes to a Lambda that updates some analytics service. A third might fan out to a webhook if the invitee has integrations enabled.
The API pod never knows or cares about email servers, Lambda, or third-party APIs failing. It publishes and returns an 'Accepted' status. Understanding this possibility came with the understanding of just how accessible Amazon's services are to one another.
SNS for API-Driven Systems
AWS SNS shines when you want clear responsibility boundaries.
Most recently I have used this in a system for API-triggered work that doesn’t need to happen immediately and for communication across service boundaries.
In a live service application an API call should do the minimum amount of work necessary to respond. Anything slow, optional, or downstream should happen after the response is sent. Otherwise the user is left waiting for a response that may be stuck in a queue; or from the users perspective gone into the Ether. SNS lets you publish an event like “something happened” that will return a quick response to the user and let other systems react independently.
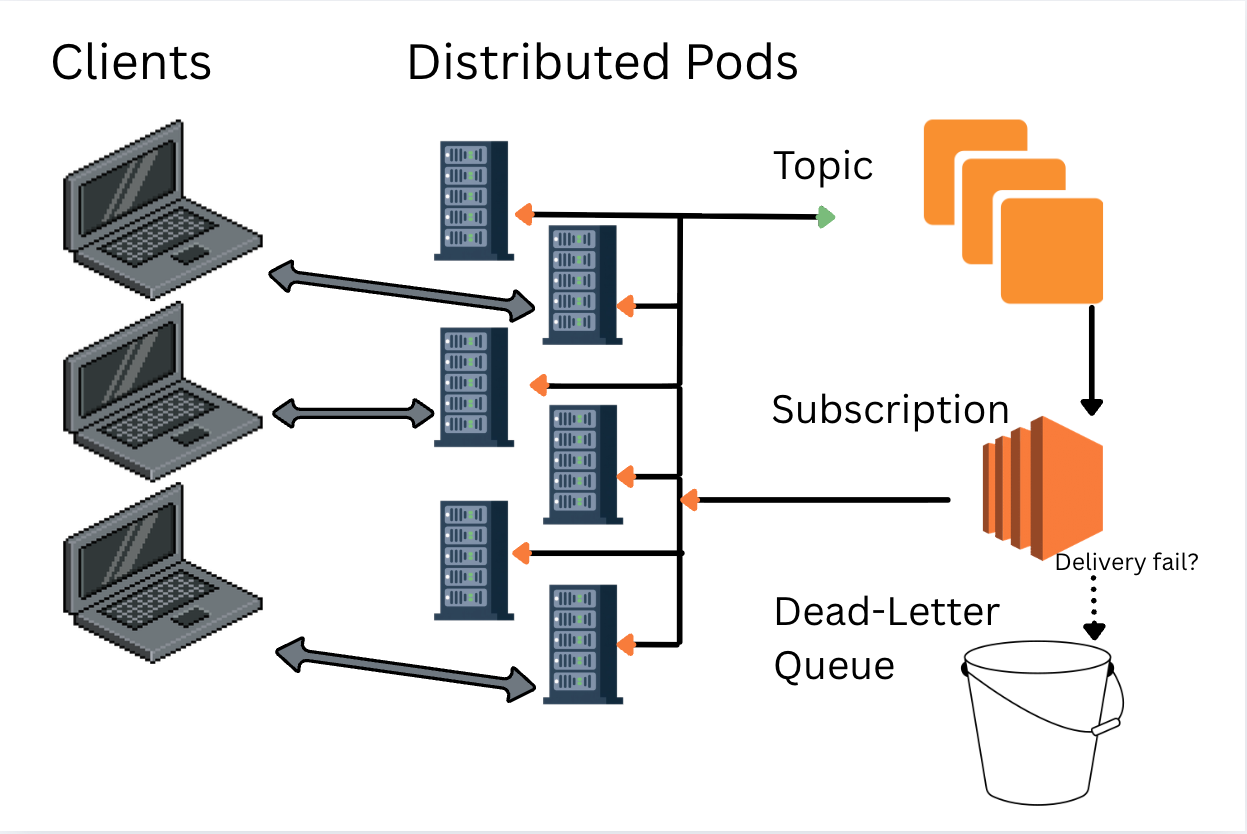
Remember Pub/Sub is not responsible for ultra-low-latency WebSocket fan-out inside the cluster. SNS handles the slower fire-and-forget cross-service events.
There are many use-cases for harnessing this power.
Async post-API side effects: Validate signatures, enrich data, or kick off ML jobs after responding to the user.
Cross-service / cross-team notifications: One service announces "project_updated" without knowing who subscribes (e.g., dashboard service, audit logger, mobile push service).
Webhook deliveries: Fire customer webhooks without blocking or retrying in-process.
Delayed or batched work: Nightly syncs, report generation, or cleanup tasks triggered by events.
Fan-out to external systems: Integrate with third-party tools (Slack, email, PagerDuty) without tight coupling.
In all of these cases with a Pub/Sub in place the API responds quickly and the rest of the system reacts in its own time.
Most mature real-time apps end up using both Redis for instant in-memory fan-out to connected WebSockets within the cluster and SNS for anything that crosses service/team/project boundaries or can tolerate seconds of delay.
Subscriptions Are Where the Real Complexity Lives
Creating a topic is easy. Publishing a message is easy. And at first glance a subscription can look almost boring.
In Clojure it might be declared simply.
(def subscriptions
[{:topic :user-invited
:protocol :http
:endpoint "/api/pubsub/handle-invite"}\])
This Clojure snippet shows a declarative description of subscriptions. The surrounding system is responsible for translating this into SNS topics, HTTP endpoints, and queue policies at startup.
When I first reached this point I remember thinking That’s it?
A topic, a protocol, and an endpoint. How bad could it be?
This is where Pub/Sub lulled me into a false sense of confidence.
That small map is carrying far more responsibility than it appears. A subscription isn’t just “where the message goes.” It’s where delivery semantics are defined. It’s where retries are decided. It’s where failures either surface or disappear.
Speaking of disappearing there was one more lesson here that didn’t fully land until later when implementing one. Dead-letter-queues (DLQ) make the timing visible.
Attaching a DLQ to an SNS subscription sounds straightforward on paper. In practice it’s another place where AWS enforces a strict order. I felt as though I was involved in a dance here, avoiding stepping on any dangling AWS appendages that haven't made it to their next planned step.
We need an SQS queue to exist first. Permissions have to be attached before the subscription can reference it. The subscription itself must be confirmed before certain attributes can be applied. Get the sequence wrong and AWS doesn’t always reject the request—it simply ignores it.
In the AWS console interface, a task like this is trivial. Simply create a topic and subscription in SNS, an empty queue in SQS, and attach them with a few clicks. There is little room for timing errors when you're clicking around a console interface and navigating between services to set this up. Now think about the code - how do you ensure this timing?
While experimenting I found that attaching a DLQ as the redrive-policy fits in nicely with the confirmation of a subscription step. This is typically where other attributes will be attached as well. Pay close attention to the allow-sns! function because this is the magic line that tells the SQS queue that - yes - it is in-fact okay to let an SNS subscription to deliver message into this queue.
(defn attach-dlq! [sns sqs subscription-arn topic-arn topic-name]
(let [sqs-url (create-queue! sqs topic-name)
sqs-arn (queue-arn sqs sqs-url)
_ (allow-sns! sqs sqs-url topic-arn)]
(set-attribute! sns subscription-arn :RedrivePolicy {:deadLetterTargetArn sqs-arn})))
(defn confirm-subscription
[sns sqs topic-arn token]
(let [topic-map (topic topic-arn)
response (.confirmSubscription sns
(->ConfirmSubscriptionRequest topic-arn token))
subscription-arn (.subscriptionArn response)]
(attach-dlq! sns sqs subscription-arn topic-arn (:name topic-map))
response))
Creating and attaching a dead-letter-queue to a subscription requires that a subscriptions not only exists, but is in a 'confirmed' state.
Messages can be dropped after retries are exhausted or when permissions prevent delivery, unless a DLQ is configured. If a queue policy is missing or misconfigured, delivery can fail silently. From the publisher’s perspective, everything looks fine. The message was “sent.” Somewhere downstream, it simply never arrived.
This is why Pub/Sub failures are so unnerving. Nothing crashes. Nothing throws. The system just… doesn’t do the thing you expected. They demand a working knowledge of AWS; not just the APIs but how those APIs behave when something goes wrong.
That’s also why experimentation matters. Reading the documentation helps but watching a message fail to deliver because of a missing permission teaches you something the docs never quite can.
Testing Without Lying to Yourself
One of the quieter challenges with SNS Pub/Sub is testing.
Mocking it poorly creates comforting illusions. Everything passes. Nothing works in production. This requires really understanding the AWS documentation. I certainly found myself scratching my head at some points wondering; What EXACTLY is Amazon expecting?
The testing approach that finally worked was a layered one.
In-memory doubles that preserved the shape of Pub/Subs topics, subscriptions, and publishing. This way the application code stayed honest.
Integration tests using LocalStack that allowed real SNS topics and subscriptions to be created locally following AWS’s exact rules.
A Clojure test example for a new SNS Topic in the LocalStack.
(context "sns integration"
(with pubsub
(start-pubsub!
{:impl :sns
:endpoint "http://localhost:4566"}))
(it "creates topics and publishes messages"
(let [topic (create-topic! @pubsub "test-events")]
(publish! @pubsub topic {:event :ping})
(should (topic-exists? @pubsub topic))
(delete-topic topic)))
Creating a Pub/Sub service that is local to the tests with the ‘with’ function. We can then spin one up on the LocalStack (provided that an instance is running), and use it to assert real topic creation and even that a message can be passed into it!
LocalStack was particularly valuable here. It validated that topic creation, subscription confirmation, IAM-style policies, and delivery all behaved the way AWS expects, importantly, before anything touched a real account. That feedback loop made a huge difference. While there is some setup involved with LocalStack once you have it configured it can provide a massive confidence boost for deliverable code with proper integration tests.
Fast unit tests told us the code made sense. LocalStack told us the infrastructure did. Both were necessary.
The Quiet Victory of Boring Infrastructure
I have found personally there’s a moment when learning new technology where understanding replaces superstition. Pub/Sub crossed that line for me once I stopped imagining it as “fancy callbacks” and “magic messaging” and started seeing it as infrastructure for selective broadcasting. Everything fell into place.
Once that clicked communication became easier to implement and services became easier to reason about. Failures became observable instead of mysterious. Scaling the project stopped being a scary thing to do and instead became.. boring.
And boring infrastructure is the best kind.
How this affects your system
If you're building a system and starting from scratch then take the pragmatic approach. Use in-process messaging while everything lives in one process. The moment that requests and connections live in different runtimes then you should begin thinking about which Pub/Sub system you should introduce.
When you do take the leap -- remember to treat your subscriptions as infrastructure and not only plumbing. Dead-letter-queues are a must for production. Always configure a DLQ before trusting a Pub/Sub system in a production environment. You wouldn't want to lose that valuable error data!
Final Thoughts from the Train Station
Pub/Sub systems like SNS are powerful precisely because they force you to think clearly about boundaries. They punish shortcuts. They scale your architecture and your understanding.. eventually.
If there’s a unifying lesson in all of this it’s that Pub/Sub forces you to be explicit and rewards you for being so. Explicit about ownership. Explicit about failure. Explicit about timing.
That explicitness can feel punishing at first. Especially when you’re staring at subscription configurations wondering why a message vanished into the void. But it’s also what makes distributed systems survivable.
Eventually the station map makes sense. You know which trains leave when, where they go, and what happens when they don’t arrive.
And once you reach that point Pub/Sub isn’t mysterious anymore. At least it wasn’t for me.
I’ve come to realize that it’s just infrastructure doing its job. Quietly, predictably and without asking you to care who’s listening.